
What Is Web Scraping?
Web scraping is the process of automatically extracting data and collecting information from the web. It could be described as a way of replacing the time-consuming, often tedious exercise of manually copy-pasting website information into a document with a method that is quick, scalable and automated. Web scraping enables you to collect larger amounts of data from one or various websites faster.

The process of scraping a website for data often consists on writing a piece of code that runs automatic tasks on our behalf. This code can either be written by yourself or executed through a specialised web scraping program. For example, by simply writing a few basic lines of code, you can tell your computer to open a browser window, navigate to a certain web page, load the HTML code of the page, and create a CSV file with the information you want to retrieve, such as a data table.
These pieces of code - called bots, web crawlers or spiders - use a web browser in your computer (i.e. Chrome, Firefox, Safari, etc) to access a web page, retrieve specific HTML elements and download them into CSV files, Excel files or even upload them directly into a database for later analysis. In short, web scraping is an automated way of copying information from the internet into a format that is more useful for the user to analyse.
The process of web scraping follows a few simple steps:
You provide your web crawler a page’s URL where the data you are interested in lives.
The web crawler starts by fetching (or downloading) a page’s HTML code - the code that represents all the text, links, images, tables, buttons and other elements of the website page you want to get information from – and store it for you to perform further actions with it.
With the HTML code fetched, you can now start breaking it down to identify the key elements you want to save into a spreadsheet or local database, such as a table with all its data.
For example, you can use web scraping to collect the results of all Premier League matches without having to manually copy-paste every results from a web page with such information. A web crawler can do this task automatically for you. You would first provide your web crawler or web scraper tools the URL of the page you want to scrape (i.e. https://www.bbc.co.uk/sport/football/premier-league/scores-fixtures). The web crawler will then fetch and download the HTML code from the URL provided. Finally, based on the specific HTML elements you requested the web crawler to retrieve it would export those elements containing match information into a downloadable CSV file for you in milliseconds.
What Is Web Scraping Used For?
Web scraping is widely used across numerous industries for a variety different purposes. Businesses often use web scraping to monitor competitor’s prices, monitor product trends and understand the popularity of certain products or services not only within their own website but across the web. These practices extend to market research, where companies seek to acquire a better understanding of market trends, research and development, and understanding customer preferences.

Investors also use web scraping to monitor stock prices, extract information about companies of interest and keep an eye on the news and public sentiment surrounding their investments. This invaluable data helps their investment decisions by offering valuable insights on companies of interest and the macroeconomic factors affecting such enterprises, such as the political landscape.
Furthermore, news and media organisations are heavily dependent on timely news analysis, thus they leverage web scraping to monitor the news cycle across the web. These media organisations are able to monitor, aggregate and parse the most critical stories thanks to the use of web crawlers.
The above examples are not exhaustive, as web scraping has dramatically evolved over the years thanks to the ever-increasing availability of data across the web. More and more companies rely on this practice to run their operations and perform thorough analysis.
What Scraping Tools Are There?
Websites vary significantly in their structure, design and format. This means that the functionality needed to scrape may vary depending on the website you want to retrieved data from. This is why specialised tools, called web scrapers, have been developed to make web scraping a lot easier and more convenient. Web scrapers provide a set of tools allowing you to create different web crawlers, each with their own predefined instructions for the different web pages you want to scrape data from.
There are two types of web scrapers: pre-built software and scraping libraries or frameworks. Pre-built scrapers often refer to browser extensions (i.e. Chrome or Firefox extensions) or scraping software. These type of scraping tools require little to no coding knowledge. They can be directly installed into your browser and are very easy to use thanks to their intuitive user interfaces. However, that simplicity also means their functionality may be limited. As a result, some complex website may be difficult or impossible to scrape with these pre-built tools. Some examples of scraping apps and extensions include:
Web Scraper (Chrome extension)
Data Scraper (Chrome extension)

Scraping frameworks and libraries offer the possibility of performing more advanced forms of scraping. These scraping frameworks, such as python’s Selenium, Scrapy or BeatifulSoup, can be easily installed in your computer using the terminal or command line. By writing a few simple lines of code, they allow you to extract data from almost any website. However, they require intermediate to advance programming experience as they are often run by writing code in a text editor and executing the code through your computer’s terminal or command line. Some example of open-source scraping frameworks include:

Scraping Best Practices. Is It Legal?
Web scraping is simply a tool. The way in which web scraping is performed determines whether it is legitimate web scraping or malicious web scraping. Before undertaking any web scraping activity, it is important to understand and follow a set of best practices. Legitimate web scraping ensures that the least amount of impact is caused to the website where the data is being scraped.

Legitimate scraping is very commonly used by a wide variety of digital businesses that rely on the harvesting of data across the web. These include:
Search engines, such as Google, analyse web content and rank it to optimise search results.
Price comparison sites collect prices and product descriptions to consolidate product information.
Market research companies evaluate trends and patterns on specific products, markets or industries.
Legitimate web scraping bots clearly identify themselves to the website by including information about the organisation or individual the bot belongs to (i.e. Google bots set their user agents as belonging to Google for easy spotting). Moreover, legitimate web scraping bots abide by a site’s scraping permissions. Websites often include a robots.txt file appended to their URLs describing which pages are permitted to be scraped and which ones disallow scraping. Examples of robots.txt permissions can be found in https://www.bbc.co.uk/robots.txt, https://www.facebook.com/robots.txt and https://twitter.com/robots.txt. Lastly, legitimate web scraping bots only attempt to retrieve what is already publicly available, unlike malicious bots that may attempt to access an organisation’s private data from its nonpublic database.
On the other side of legitimate web scraping there are certain individuals and organisations that attempt to illegally leverage the capabilities of web scraping to directly undercut competitor prices or steal copyrighted content. This may often cause financial damage to a website’s organisation. Malicious web scraping bots often ignore the robots.txt permissions, therefore extracting data without the permission of the website owner. They also impersonate legitimate bots by identifying themselves as other users or organisations to bypass bans or blocks. Some examples of malicious web scraping include spammers that attempt to retrieve contact and personal detailed information of individuals to later send fraudulent or false advertising to a large number of user inboxes.
This increase in illegal scraping activities have significantly damaged the reputation of web scraping over the years. Substantial controversy has been drawn to web scraping, fueling a lot of misconceptions surrounding the practice of automatic extraction of publicly available web data. Nevertheless, web scraping is a legal practice when performed ethically and responsibly. Reputable corporations such as Google heavily rely on web scraping to run their platforms. In return, Google provides considerable benefits to the websites being scraped by generating large amounts of traffic to such websites. Ethical and responsible web scraping means the following:
Read the robots.txt page of the website you want to scrape and look out for disallowed pages (i.e. https://www.atptour.com/robots.txt).
Read the Terms of Service for any mention of web scraping-related restrictions.
Be mindful of the website’s bandwidth by spreading your data requests (i.e. setting a delay and interval of 10-15 seconds per request instead of hundreds at once).
Don’t publish any content that was not meant to be published in the first place by the original website.
Where To Find Sports Data
A league’s official website is a good starting point to gather basic sports data about a team’s or athletes performance stats and start building a robust sports analytics dataset. However, nowadays, many unofficial websites developed by sports enthusiasts and media websites contain invaluable information that can be scraped for sports analysis.
For example, in the case of football, the Premier League website’s Terms & Conditions permits you to “download and print material from the website as is reasonable for your own private and personal use”. This means that you may scrape their league data to obtain information about fixtures, results, clubs and players for your own analysis. Similarly, BBC Sports currently permits the scraping of its pages containing league tables and match information.
The data obtained from the Premier League and BBC Sports websites can later be easily augmented by scraping additional non-official websites that offer further statistics on match performances and other relevant data points in the sport. Some example websites include:
The same process applies to any other sports. However, the structure and availability of statistics in different official sport websites significantly vary from sport to sport. The popularity of the sport also dictates the number of non-official analytical websites offering relevant statistics to be scraped.
Scraping Example: Premier League Table
Below is a practical example on how to scrape the BBC Sports website to obtain the Premier League table using various scraping methods. The examples are designed as of the structure of BBC’s website at the time the article is published. Possible future changes by the BBC to their Premier League table page could mean that the HTML of the page slightly changes, therefore the scraping code in the example below may required some readjustment to reflect those design changes.
Using Web Scraper (Google Chrome extension)
1. Install Web Scraper (free) in your Chrome browser.
2. Once installed, an icon on the top right hand side of your browser would appear. This icon opens a small window with instructions and documentation on how to use Web Scraper.
3. Go to the BCC Sports website: https://www.bbc.co.uk/sport/football/tables
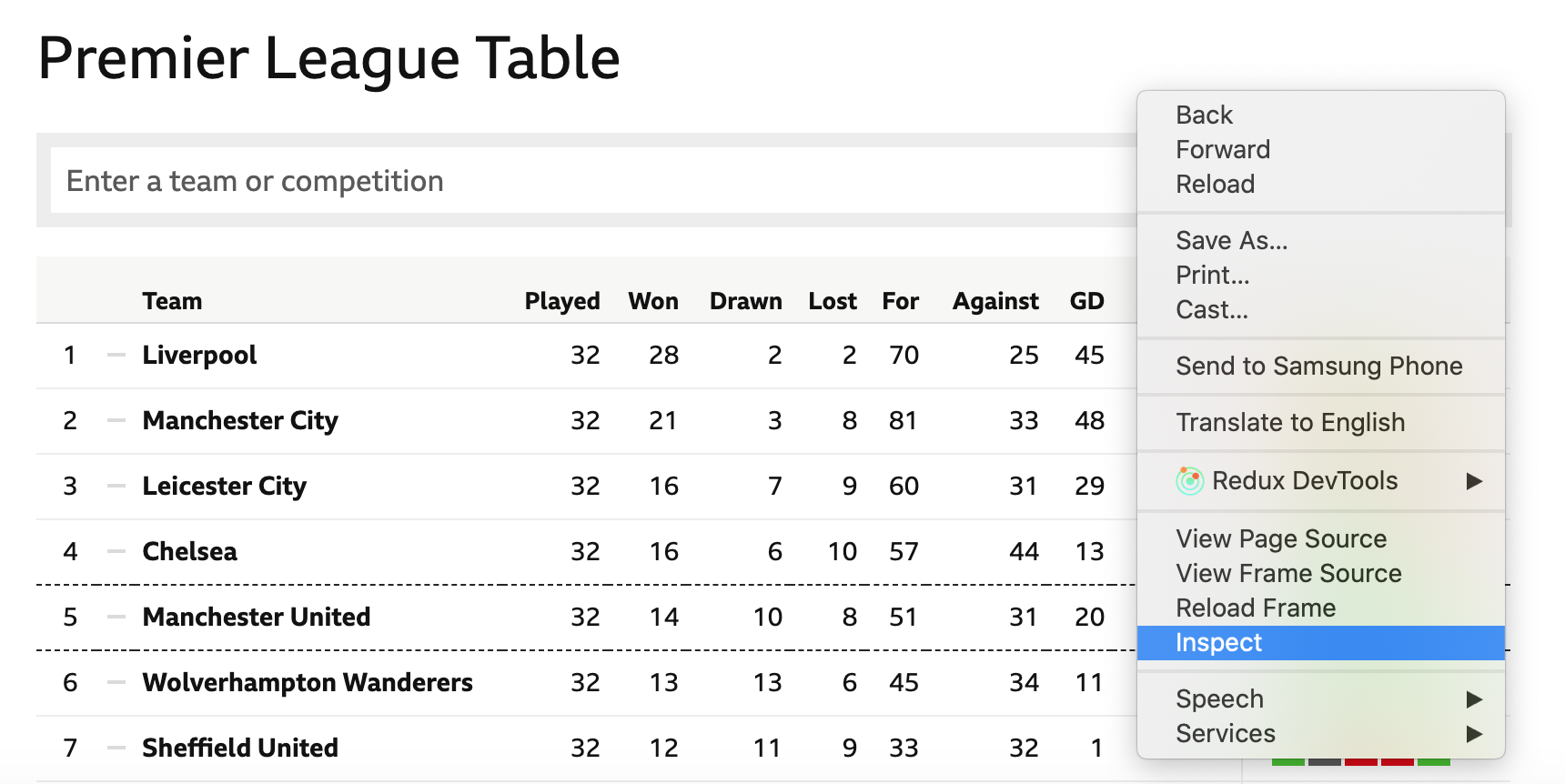
4. Right click anywhere on the page and select “Inspect” to open the browser Dev Tools (or press Option + ⌘ + J on a Mac, or Shift + CTRL + J on a Windows PC).
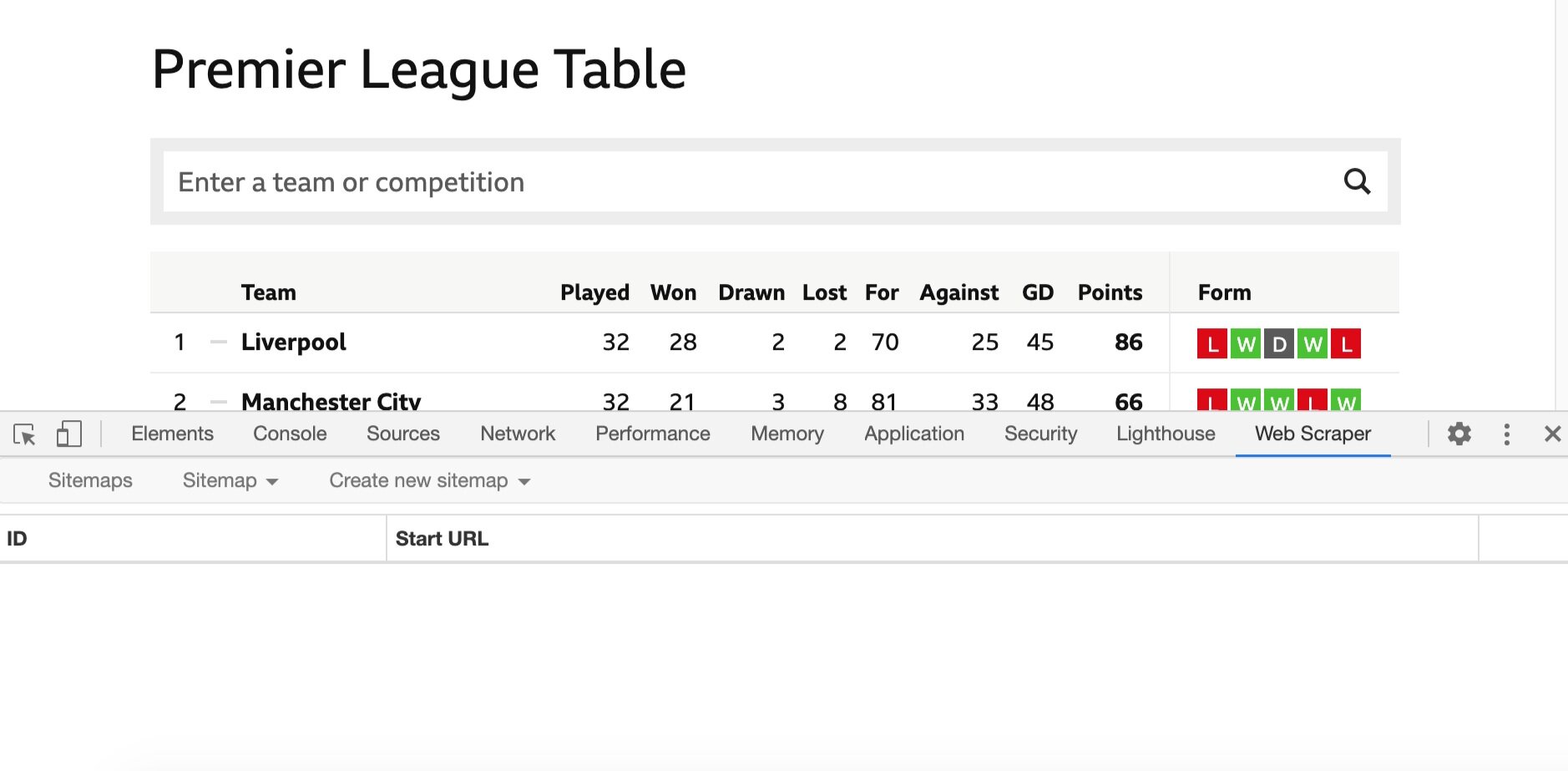
5. Make sure the Dev Tools sidebar is located at the bottom of the page. You can change its position under options and Dock side within the Inspect sidebar.
6. Navigate to the Web Scraper tab. This is where you can use the newly installed Web Scraper tool.
7. To scrape a new page, you first need to create a new web crawler or spider by selecting “Create new sitemap”.
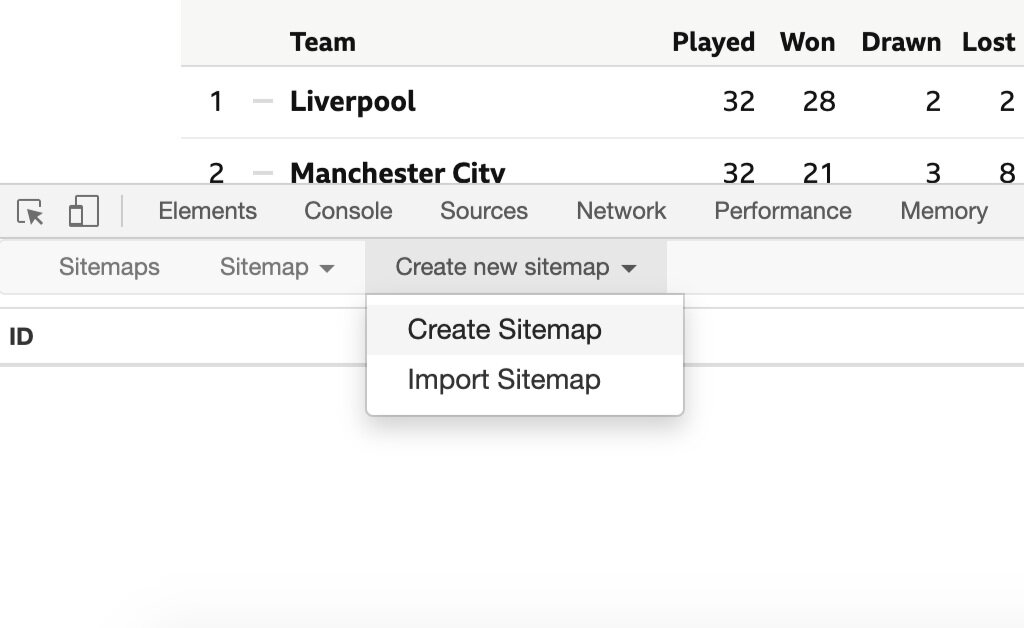
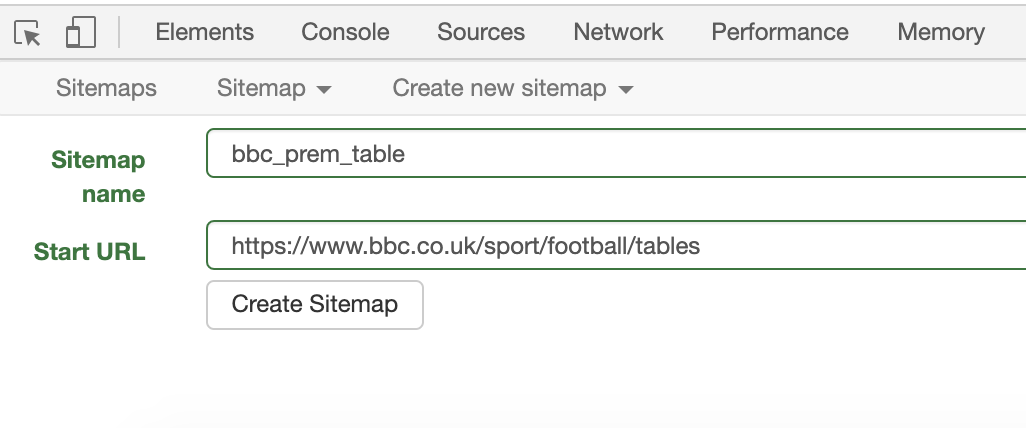
8. Give the new sitemap a comprehensive name, in this case “bbc_prem_table” and then paste the URL of the web page you want to obtain data from: https://www.bbc.co.uk/sport/football/tables. Then click on “Create sitemap”.
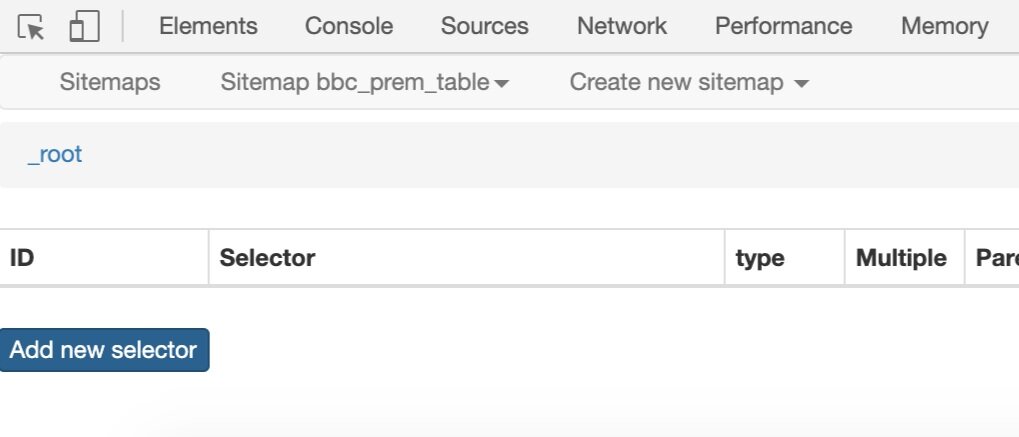
9. Now that the spider is created, you would need to specify the specific elements of the page you would like data to be extracted from. In this example, we are looking to extract the table. To do so, click on “Add a new selector” to specify the HTML element that the web crawler needs to select and look for data in.
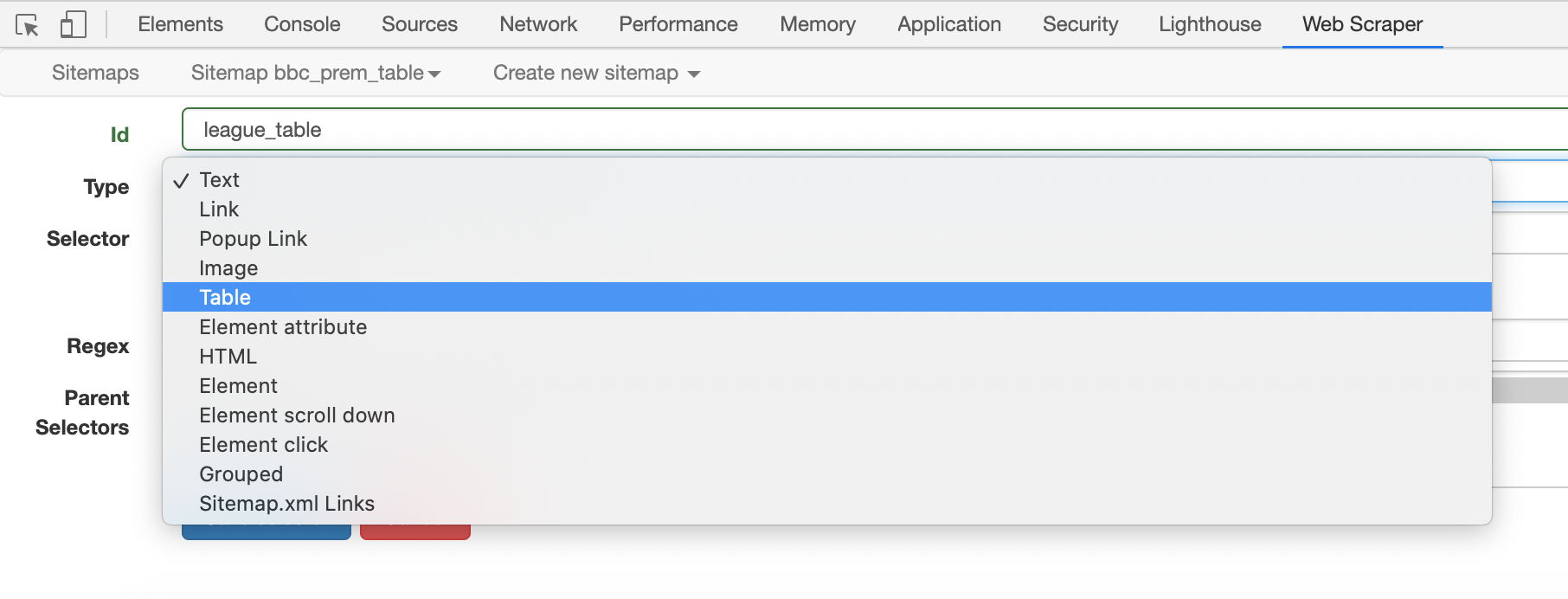
10. Give the selector a lowercase name under “Id” and set the Type as a “Table”, since we will be extracting data from a table element within the HTML code of the page.
11. Under the Selector field, you would need to specify the specific element on the page that you would like to target. Since we have already specified in the field above that the element is a Table, by using the option “Select” and then clicking on the league table on the BBC page, Web Scraper will auto-select the right elements for us to target. Once you click on “Select” under the “Selector” field, hover over the table until it turns green. Once you are certain that the table is correctly highlighted, click on it until it turns read and the input bar reads “table”. Then press “Done selecting!” to confirm your selection.
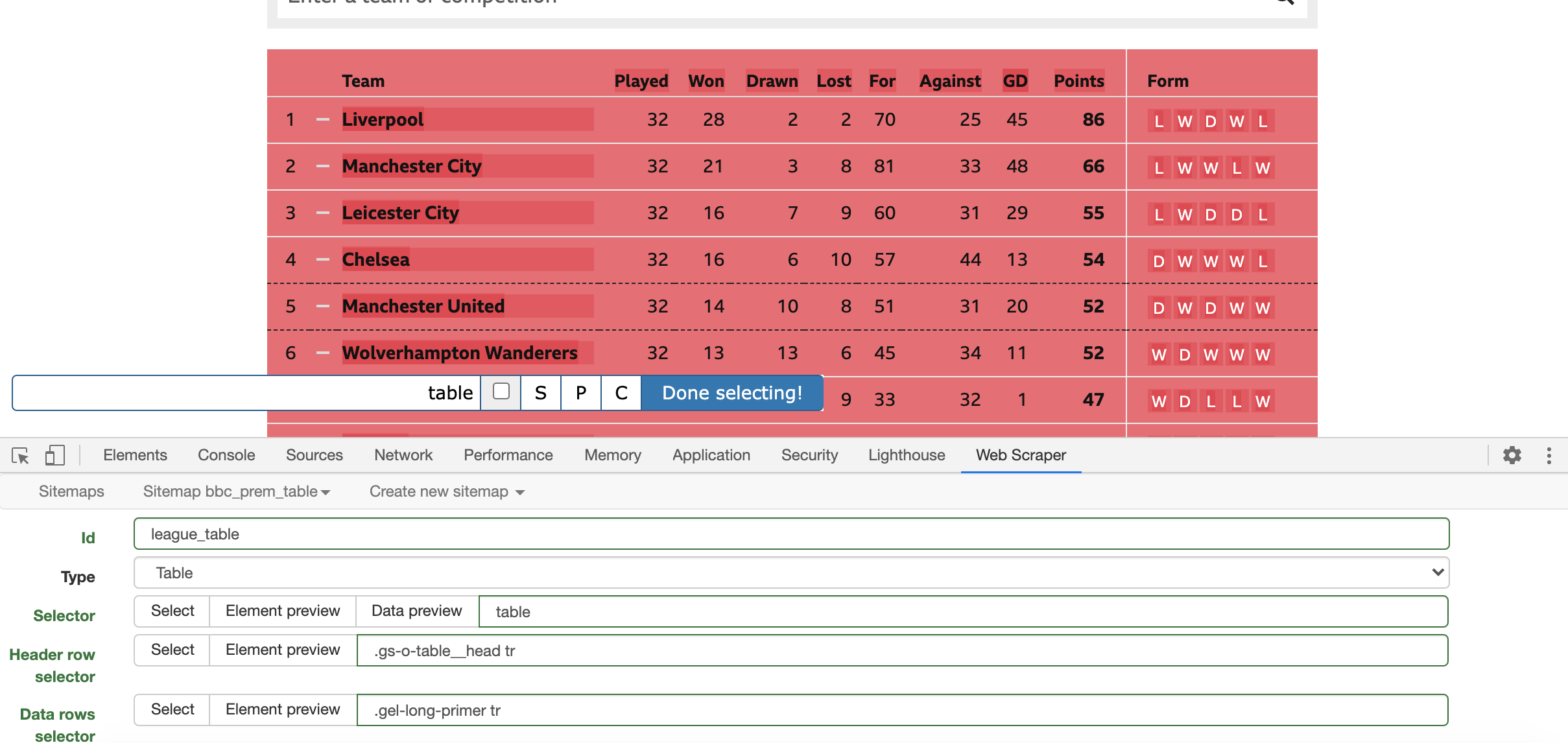
12. The table header and row fields should now be automatically populated by Web Scraper, and a new field called Table columns should have appeared at the button of the window. Make sure the columns have been correctly captured from the table and change the column names to lowercase, since Web Scraper does not allow for uppercase characters.
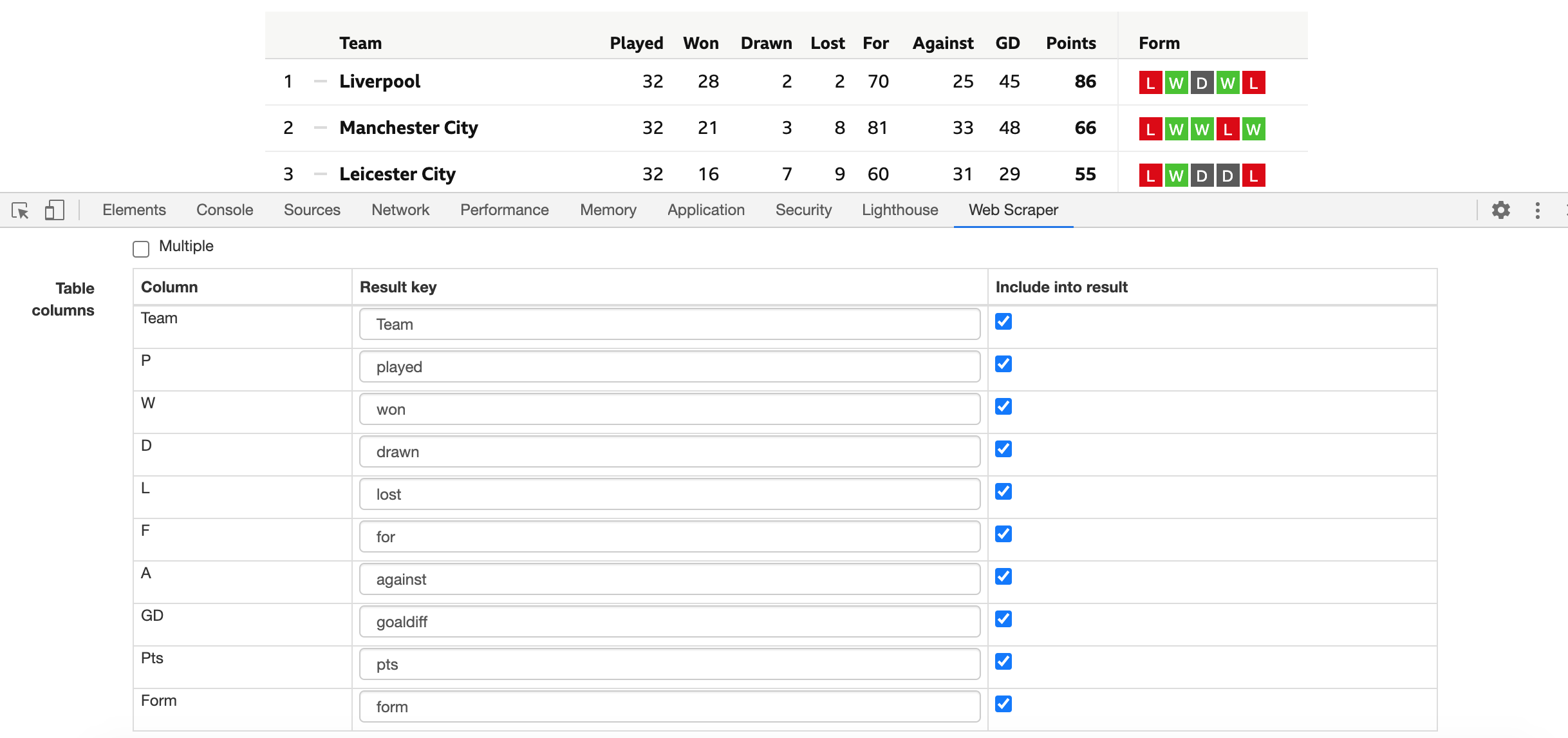
13. Above the Table columns. Check the box for “Multiple” items so that the web crawler extracts more than one row of data from the table, rather than just the data for the first row (first team).
14. Now that the selector is correctly configured, click on “Save selector” to confirm all the settings and create the selector.
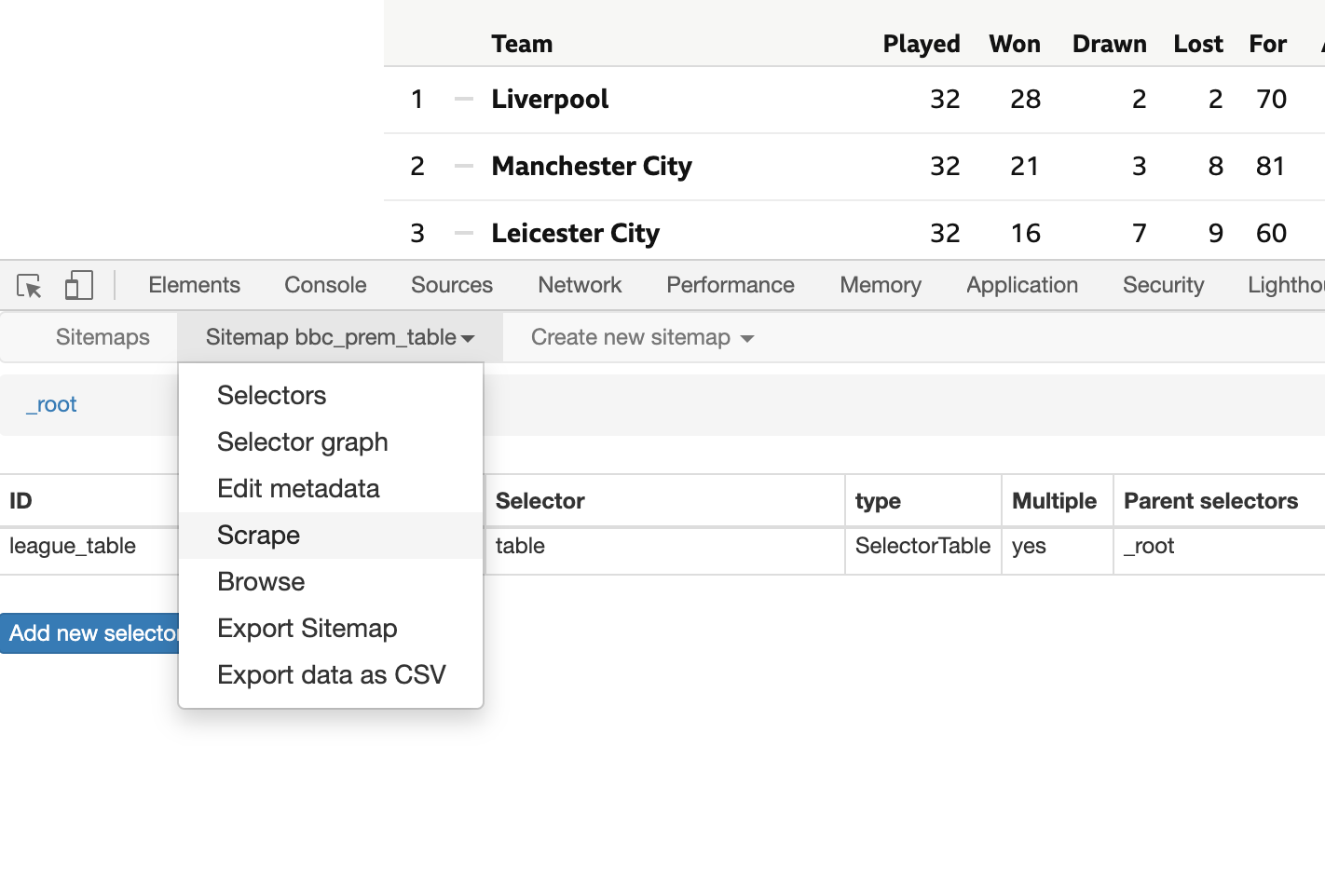
15. You are now ready to scrape the table. Go to the second option of the top menu (Sitemap + name of your new sitemap) and select “Scrape”. Leave the intervals and delay to 2s (2000ms) and select “Start scraping”. This will open and close a new Chrome window where your web crawler will attempt to extract the data.
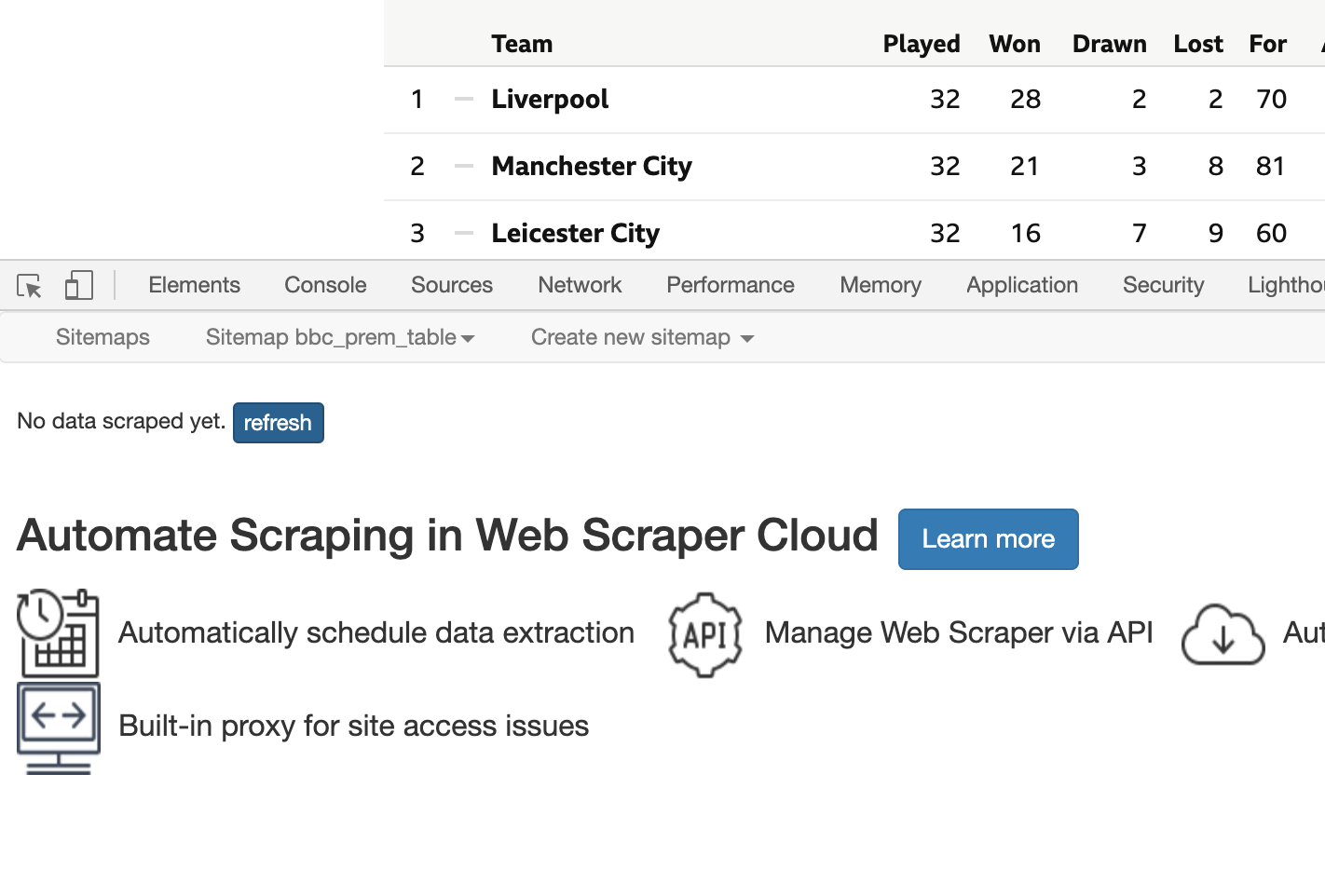
16. Once the scraping is done. Click on “refresh” next to the text “No data scraped yet”. This will display the data scraped.
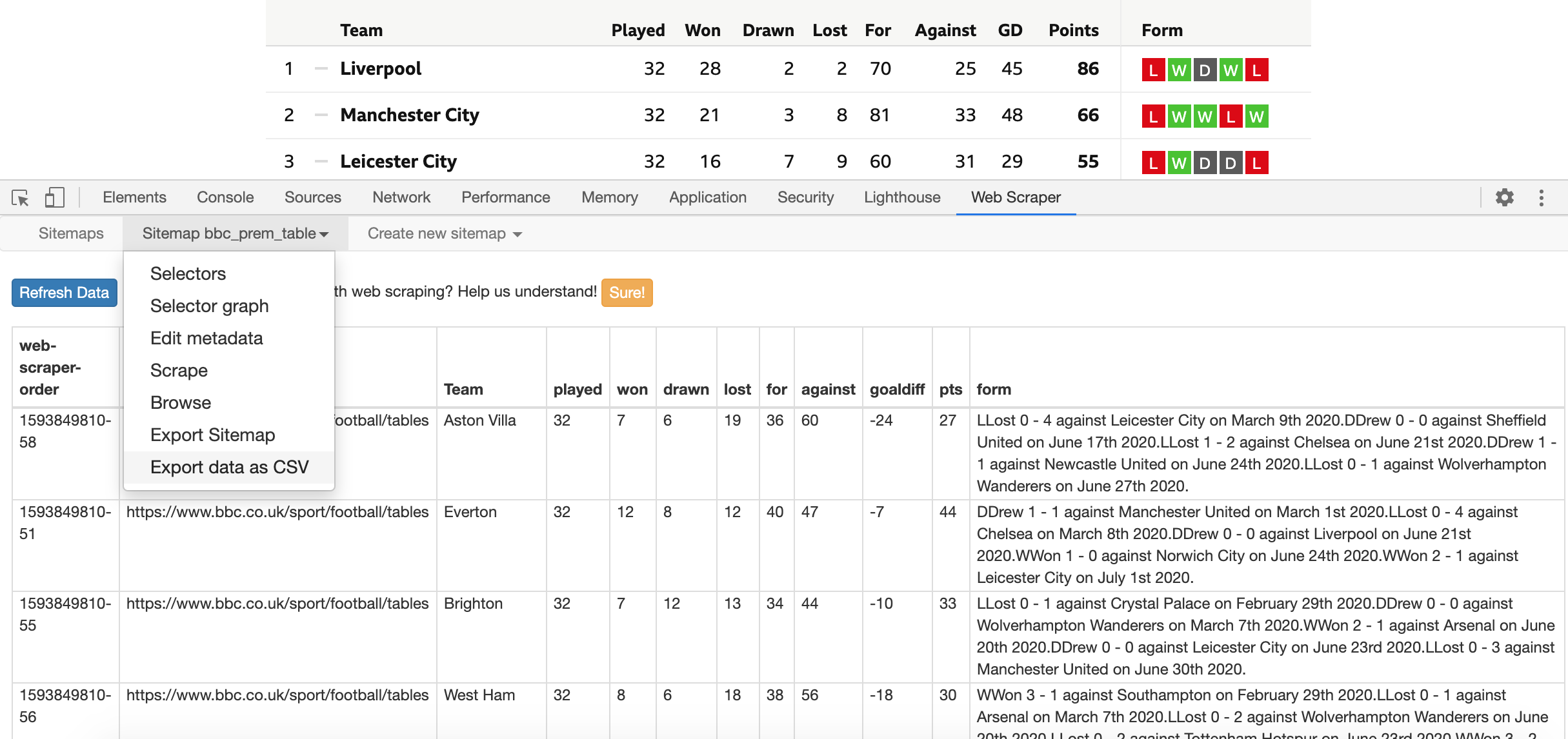
17. To download the data to a CSV file. Select the second option on the top menu once again and click on “Export data as CSV”. This will download a file with the Premier League data you have just scraped from BBC Sports.
Using Python’s BeautifulSoup
1. Open your computer’s command line (Windows) or Terminal (Mac).
2. Install PIP to your computer by typing the below line in your command line. PIP is a python package manager that allows you to download and manage packages that are not already available with the standard python installation.
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py3. Install Python, BeautifulSoup and Requests packages. These packages are required to write and execute the python code that will perform your scraping. Enter the following lines and press Enter, one by one, in your command line or terminal:
pip install pythonpip install requestspip install bs44. Open a text editor. This is where you will write your scraping code. If you don’t already have a text editor in your computer, consider downloading and installing Atom or SublimeText.
5. Create a new file and name it, for example, “prem_table_spider.py”. The “.py” extension at the end of the file name tells you text editor that it is a python file. Save the file to your Desktop for easier access later on.
6. The first lines of code refers to the package imports necessary to run the remaining of the script you will write. The packages needed in this case are “requests“ to get the HTML from the BBC page, “bs4” to use the tools provided by BeautifulSoup to select elements within the downloaded HTML, and “csv” to create a new CSV file where the data will be exported to.
import requests
from bs4 import BeautifulSoup
import csv7. The next line of code will create a blank CSV file to store the collected data. Use the “csv.writer” function to create the file and give the file a name (i.e. prem_table_bs) and a mode of write (“w”) to enable python to write into this newly created file.
output_file = csv.writer(open('prem_table_bs.csv', 'w'))8. After the CSV file is created, we will then want the code to create some table headers for the data we are going to be exporting. Use a “writerow” function that adds a new row of data to the CSV file. This row of that will simply be the header names that are shown in the league table from the BBC page.
output_file.writerow(['Position', 'Team', 'Played', 'Won', 'Drawn', 'Lost', 'For', 'Against', 'GD', 'Points'])9. Now that the file is setup, the next steps will consist on writing the actual web scraping code. The first step is to provide the web crawler with the URL of the page we want to extract information from. This is done using the requests package. We use the “requests.get” function with the URL as an argument to extract the HTML from the BBC Sport football tables page. We save the results of this request as a variable called “result”.
result = requests.get("https://www.bbc.co.uk/sport/football/tables")10. From the “result” obtained when getting the page’s HTML, we are only interested in its content. The get function offers other elements, such as headers or response status codes, which will not be of use for us in this example. To specify that we only want to work with the content, we save the “content” from the “result” into a new variable labelled “src” (source) for later use.
src = result.content11. We have successfully extracted the HTML code from the BBC Sports page and saved it into a variable “src”. We can now start using BeautifulSoup on “src” to select the specific elements from the page that we want to extract (i.e table, table rows and table data). First, we need to tell BeautifulSoup to use the “src” variable we’ve just created containing the HTML content from the BBC Sports page by writing the following line. This line of code will set a new BeautifulSoup HTML parser variable called “soup” that uses the “src” contents:
soup = BeautifulSoup(src, 'html.parser')12. Now the BeautifulSoup is connected to the BBC page’s HTML from the “src” variable, we can breaking down the HTML elements inside of “src” until we find the data we are after. Since we are looking for a table, this will involve selecting the <table> HTML element, extracting the <tr> (table rows) and then gathering each <td> (table data) from each row.
First, we set a new variable called “table” that represents all the <table> elements from the page. Since we use the “find_all_” function, we will receive a list of all tables. However, since there is only one table on the BBC’s page, that list will only contain one item. To retrieve the league table from the “table” list we need to set a new variable called “league_table” refers to the first item from such list (at index 0).
table = soup.find_all("table")
league_table = table[0]13. With the league table now selected, we can now extract each row of data by running a new “find_all” function from the league_table that looks for all HTML elements with the tag <tr> (table row). Each row of the table will be a different team therefore we can label this new list of table rows “teams”.
teams = league_table.find_all("tr")14. Finally, we can now create a for loop that iterates through every row in the table and extracts the text from every column item (<td> or table data). On every loop, python will assign the values of each <td> element in the row to a specific variable (i.e. the first element at index 0 will be league position of the team). After every loop (row) is processed, a new row of data will be written in the CSV file that was set up at the start of the code. Save the file. This is your completed scraping code.
for team in teams[1:21]:
stats = team.find_all("td")
position = stats[0].text
team_name = stats[2].text
played = stats[3].text
won = stats[4].text
drawn = stats[5].text
lost = stats[6].text
for_goals = stats[7].text
against_goals = stats[8].text
goal_diff = stats[9].text
points = stats[10].text
output_file.writerow([position, team_name, played, won, drawn, lost, for_goals, against_goals, goal_diff, points])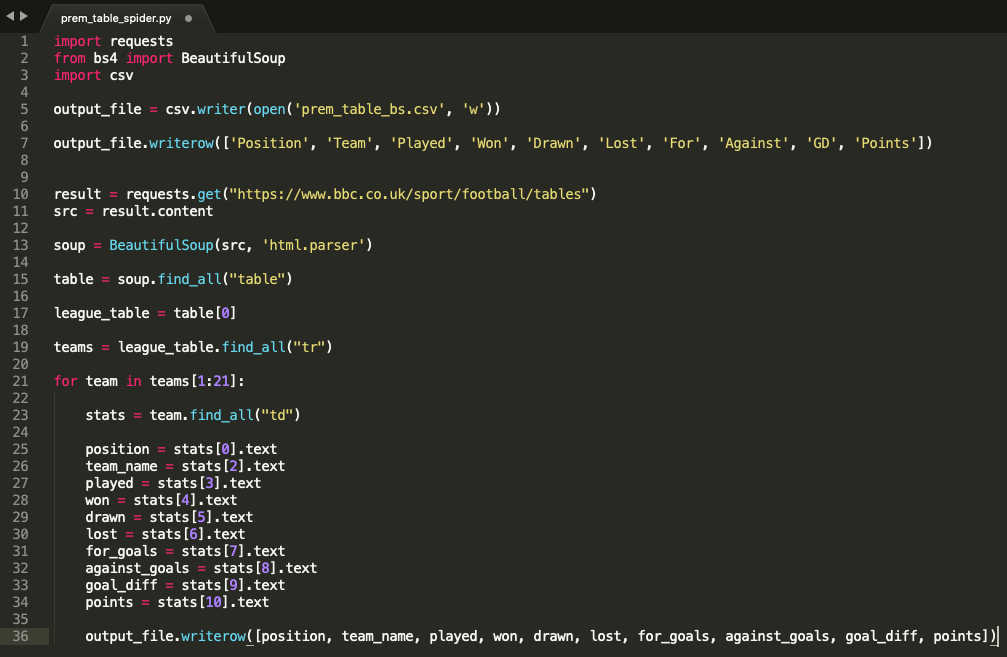
15. To run the code, open your command line or terminal once again. Navigate to the Desktop where you code file was saved. You can navigate backwards through your directories by typing “cd ..” in the command line, and navigate into a specific directory by typing the name or path of the directory after “cd” (i.e. “cd name_of_folder”). Once you are located in your Desktop directory (the name of the directory appears on the left hand side of each command line), you can run the web crawler file using the following command:
python prem_table_spider.pyOnce run, you should find a new CSV file inside your Desktop folder that contains the Premier League table data you have just scraped.

Citations
Imperva (2020). Web scraping. Imperva. Link to article.
Perez, M. (2019). What is Web Scraping and What is it Used For? Parsehub. Link to article.
Rodriguez, I. (). What Is Pip? A Guide for New Pythonistas. Real Python. Link to article.
Scrapinghub. (2019). What is web scraping? Scrapinghub. Link to article.
Toth, A. (2017). Is Web Scraping Legal? 6 Misunderstandings About Web Scraping. Import.io. Link to article.